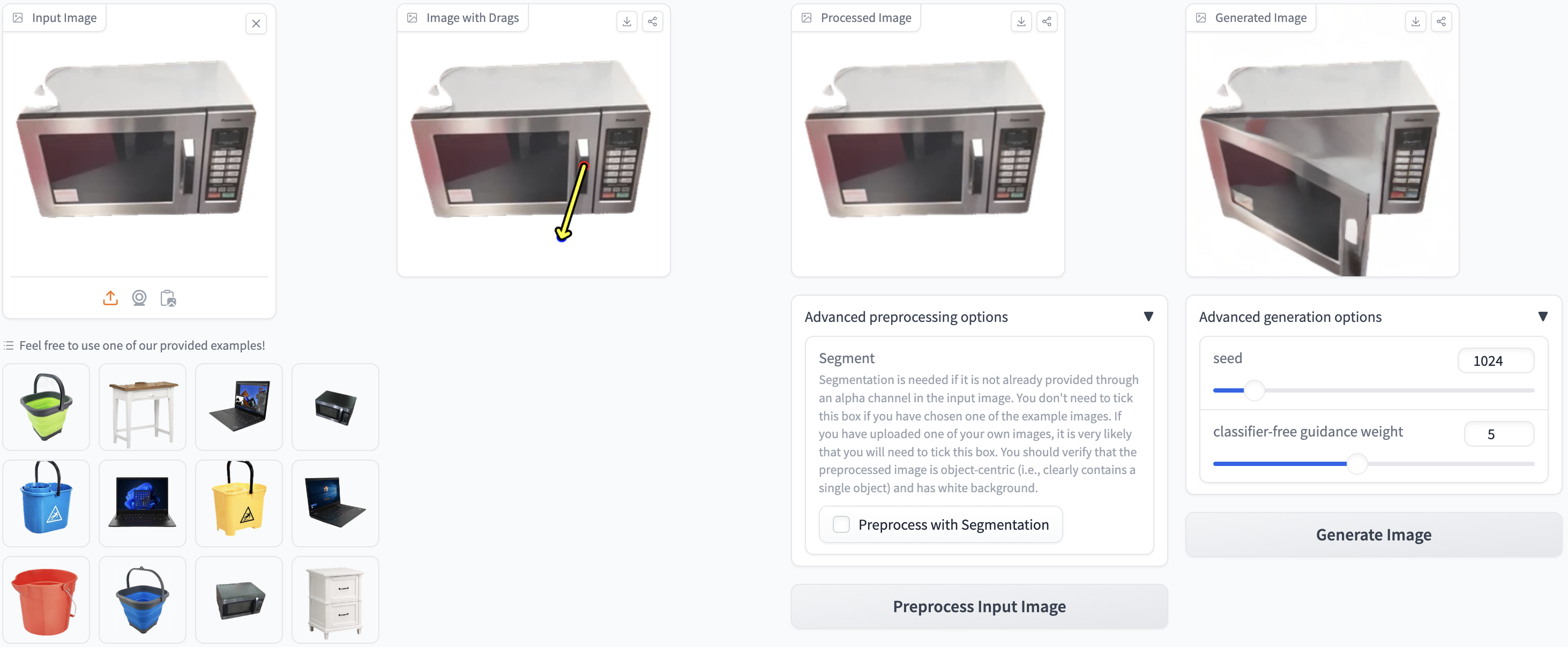
We introduce DragAPart, a method that, given an image and a set of drags as input, can generate a new image of the same object in a new state, compatible with the action of the drags. Differently from prior works that focused on repositioning objects, DragAPart predicts part-level interactions, such as opening and closing a drawer. We study this problem as a proxy for learning a generalist motion model, not restricted to a specific kinematic structure or object category. To this end, we start from a pre-trained image generator and fine-tune it on a new synthetic dataset, Drag-a-Move, which we introduce. Combined with a new encoding for the drags and dataset randomization, the new model generalizes well to real images and different categories. Compared to prior motion-controlled generators, we demonstrate much better part-level motion understanding.
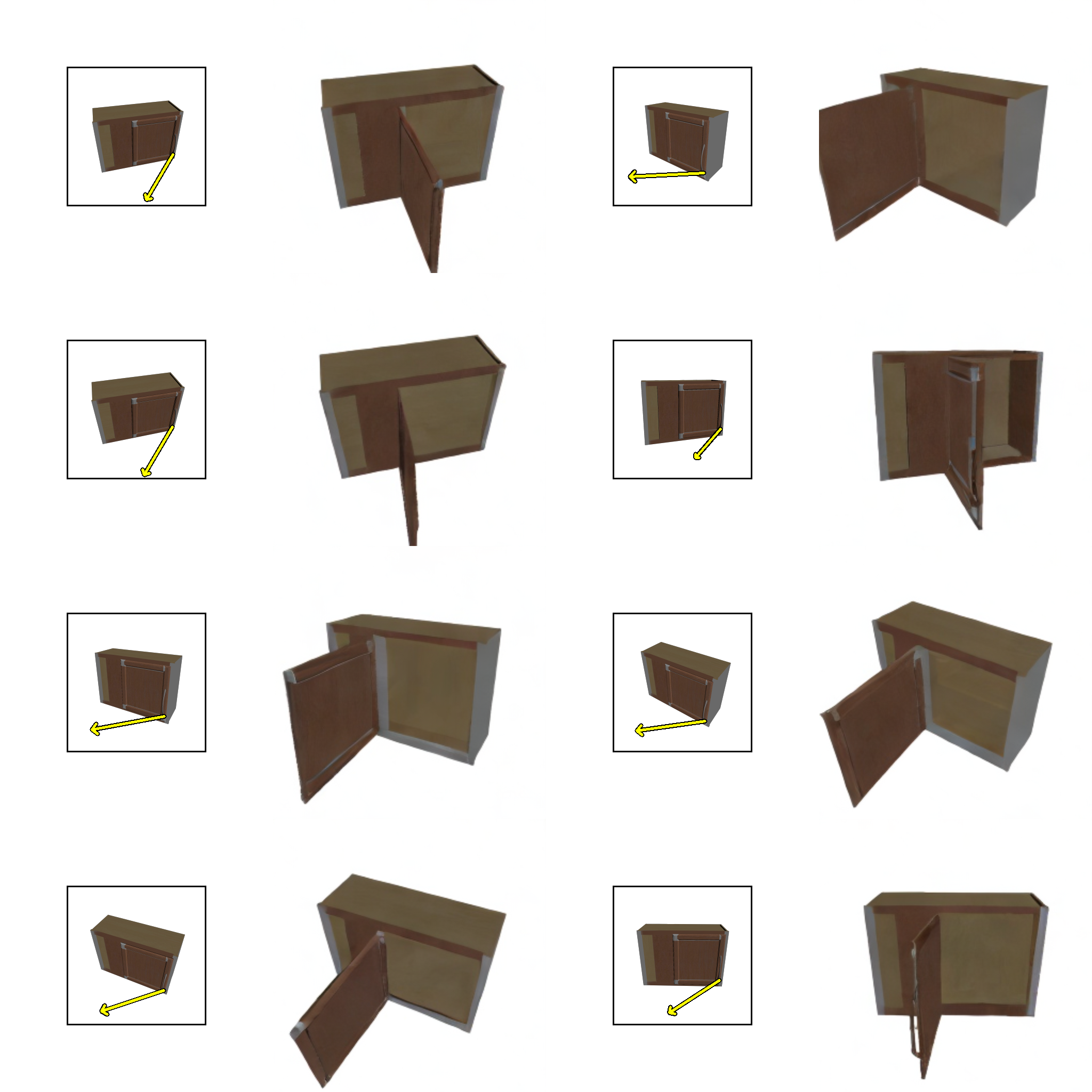
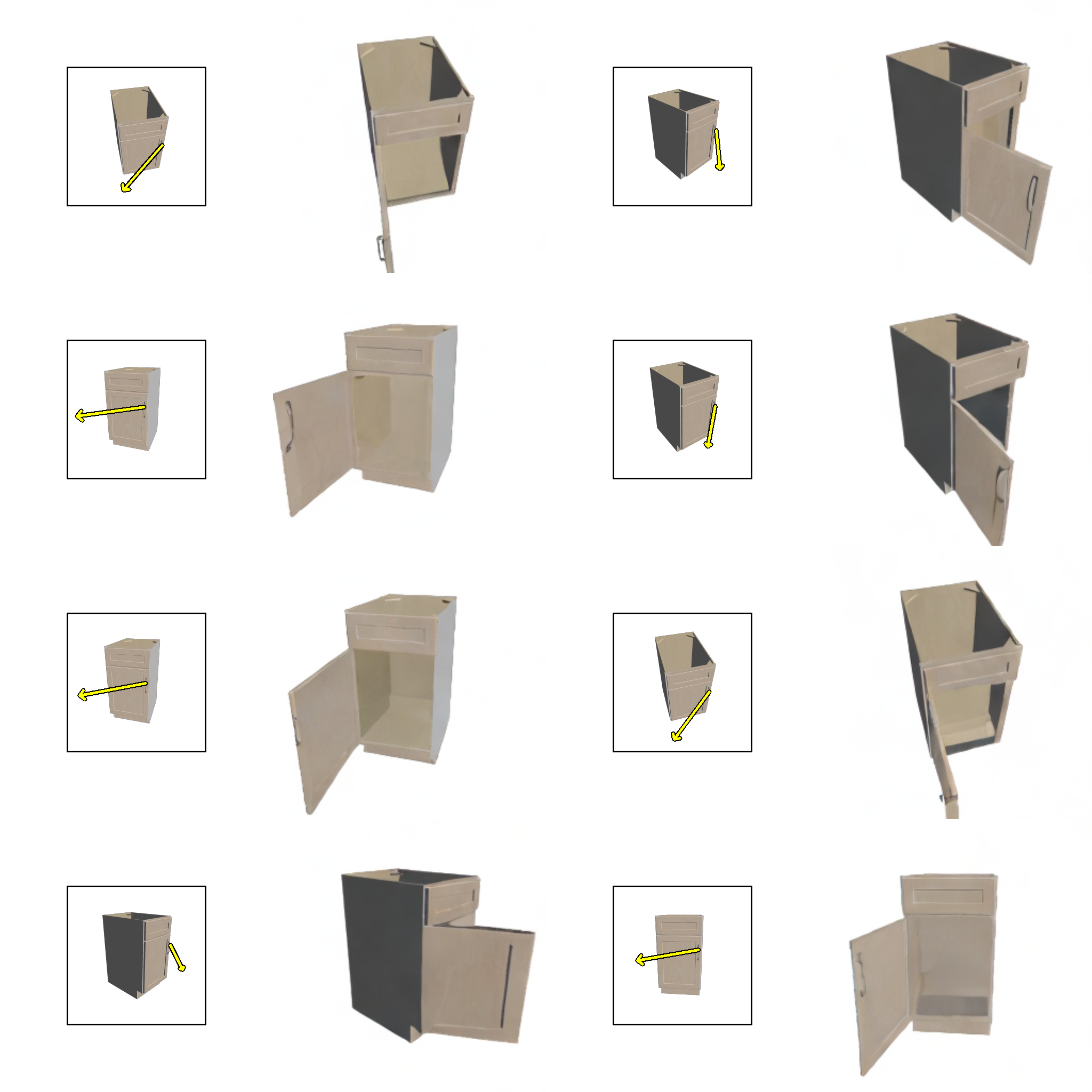
Our model is capable of preserving fine-grained texture details, generating reasonable shades, handling thin structures, compositing multi-part motion, "dreaming" up internal structures of the object, and generalizing to categories not seen during training.

Our model can be used to understand how the movable parts of an object move in response to a drag. Given a 3D mesh with parts pre-segmented and a 3D drag on the mesh, the type of motion (i.e., revolute or prismatic) and the corresponding parameters (e.g., axis of rotation or translation) can be inferred by using the generated images as psuedo ground truth and optimizing the parameters over the image RGB loss. This also indicates that our model is relatively consistent across different viewpoints.
Try it yourself: Move the slider to see the inferred 3D motion.


Input 3D Model
Generated Psuedo Ground Truth





Input 3D Model
Generated Psuedo Ground Truth


Input 3D Model
Generated Psuedo Ground Truth
The internal features of our DragAPart model contain richer part-level information than alternatives. We explore how to use them to segment the movable parts of an object in 2D, prompted by a few drags.

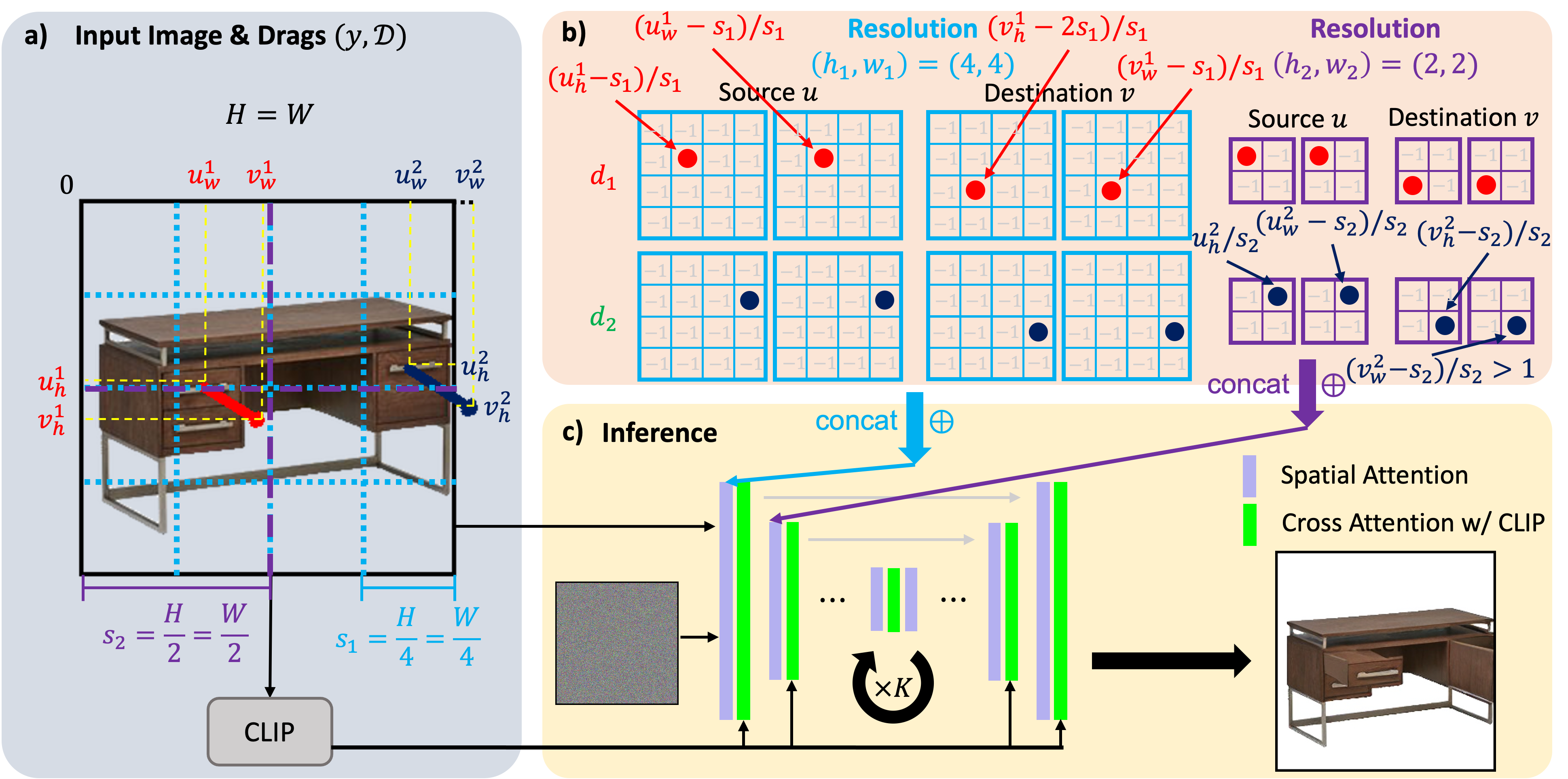
(a) Our model takes as input a single RGB image and one or more drags, and generates a second image that reflects the effect of the drags. (b) We propose a novel flow encoder, which enables us to inject the motion control into the latent diffusion model at different resolutions more efficiently. Instead of representing the sparse drags as a flow image and downsizing it with a convolutional network, we assign different channels to different drags and use separate channels to encode the drag source and the drag termination. (c) At inference time, our model generalizes to real data, synthesizing physically-plausible part-level dynamics.
@article{li2024dragapart,
title = {DragAPart: Learning a Part-Level Motion Prior for Articulated Objects},
author = {Li, Ruining and Zheng, Chuanxia and Rupprecht, Christian and Vedaldi, Andrea},
journal = {arXiv preprint arXiv:2403.15382},
year = {2024}
}We would like to thank Minghao Chen, Junyu Xie and Laurynas Karazija for insightful discussions. This work is in part supported by a Toshiba Research Studentship and ERC-CoG UNION 101001212.